在尽可能短的篇幅里,将所有集合与并发集合的特征,实现方式,性能捋一遍。适合所有”精通Java”其实还不那么自信的人阅读。
List
ArrayList
以数组实现。节约空间,但数组有容量限制。超出限制时会增加50%容量,用System.arraycopy()复制到新的数组,因此最好能给出数组大小的预估值。默认第一次插入元素时创建大小为10的数组。
按数组下标访问元素–get(i)/set(i,e) 的性能很高,这是数组的基本优势。
直接在数组末尾加入元素–add(e)的性能也高,但如果按下标插入、删除元素–add(i,e), remove(i), remove(e),则要用System.arraycopy()来移动部分受影响的元素,性能就变差了,这是基本劣势。
LinkedList
以双向链表实现。链表无容量限制,但双向链表本身使用了更多空间,也需要额外的链表指针操作。
按下标访问元素–get(i)/set(i,e) 要悲剧的遍历链表将指针移动到位(如果i>数组大小的一半,会从末尾移起)。
插入、删除元素时修改前后节点的指针即可,但还是要遍历部分链表的指针才能移动到下标所指的位置,只有在链表两头的操作–add(), addFirst(),removeLast()或用iterator()上的remove()能省掉指针的移动。
CopyOnWriteArrayList
并发优化的ArrayList。用CopyOnWrite策略,在修改时先复制一个快照来修改,改完再让内部指针指向新数组。
因为对快照的修改对读操作来说不可见,所以只有写锁没有读锁,加上复制的昂贵成本,典型的适合读多写少的场景。如果更新频率较高,或数组较大时,还是Collections.synchronizedList(list),对所有操作用同一把锁来保证线程安全更好。
增加了addIfAbsent(e)方法,会遍历数组来检查元素是否已存在,性能可想像的不会太好。
补充
无论哪种实现,按值返回下标–contains(e), indexOf(e), remove(e) 都需遍历所有元素进行比较,性能可想像的不会太好。
没有按元素值排序的SortedList,在线程安全类中也没有无锁算法的ConcurrentLinkedList,凑合着用Set与Queue中的等价类时,会缺少一些List特有的方法。
Map
HashMap
以Entry[]数组实现的哈希桶数组,用Key的哈希值取模桶数组的大小可得到数组下标。
插入元素时,如果两条Key落在同一个桶(比如哈希值1和17取模16后都属于第一个哈希桶),Entry用一个next属性实现多个Entry以单向链表存放,后入桶的Entry将next指向桶当前的Entry。
查找哈希值为17的key时,先定位到第一个哈希桶,然后以链表遍历桶里所有元素,逐个比较其key值。
当Entry数量达到桶数量的75%时(很多文章说使用的桶数量达到了75%,但看代码不是),会成倍扩容桶数组,并重新分配所有原来的Entry,所以这里也最好有个预估值。
取模用位运算(hash & (arrayLength-1))会比较快,所以数组的大小永远是2的N次方, 你随便给一个初始值比如17会转为32。默认第一次放入元素时的初始值是16。
iterator()时顺着哈希桶数组来遍历,看起来是个乱序。
在JDK8里,新增默认为8的閥值,当一个桶里的Entry超过閥值,就不以单向链表而以红黑树来存放以加快Key的查找速度。
LinkedHashMap
扩展HashMap增加双向链表的实现,号称是最占内存的数据结构。支持iterator()时按Entry的插入顺序来排序(但是更新不算, 如果设置accessOrder属性为true,则所有读写访问都算)。
实现上是在Entry上再增加属性before/after指针,插入时把自己加到Header Entry的前面去。如果所有读写访问都要排序,还要把前后Entry的before/after拼接起来以在链表中删除掉自己。
TreeMap
以红黑树实现,篇幅所限详见入门教程。支持iterator()时按Key值排序,可按实现了Comparable接口的Key的升序排序,或由传入的Comparator控制。可想象的,在树上插入/删除元素的代价一定比HashMap的大。
支持SortedMap接口,如firstKey(),lastKey()取得最大最小的key,或sub(fromKey, toKey), tailMap(fromKey)剪取Map的某一段。
ConcurrentHashMap
并发优化的HashMap,默认16把写锁(可以设置更多),有效分散了阻塞的概率,而且没有读锁。
数据结构为Segment[],Segment里面才是哈希桶数组,每个Segment一把锁。Key先算出它在哪个Segment里,再算出它在哪个哈希桶里。
支持ConcurrentMap接口,如putIfAbsent(key,value)与相反的replace(key,value)与以及实现CAS的replace(key, oldValue, newValue)。
没有读锁是因为put/remove动作是个原子动作(比如put是一个对数组元素/Entry 指针的赋值操作),读操作不会看到一个更新动作的中间状态。
ConcurrentSkipListMap
JDK6新增的并发优化的SortedMap,以SkipList实现。SkipList是红黑树的一种简化替代方案,是个流行的有序集合算法,篇幅所限见入门教程。Concurrent包选用它是因为它支持基于CAS的无锁算法,而红黑树则没有好的无锁算法。
很特殊的,它的size()不能随便调,会遍历来统计。
补充
关于null,HashMap和LinkedHashMap是随意的,TreeMap没有设置Comparator时key不能为null;ConcurrentHashMap在JDK7里value不能为null(这是为什么呢?),JDK8里key与value都不能为null;ConcurrentSkipListMap是所有JDK里key与value都不能为null。
Set
Set几乎都是内部用一个Map来实现, 因为Map里的KeySet就是一个Set,而value是假值,全部使用同一个Object。Set的特征也继承了那些内部Map实现的特征。
- HashSet:内部是HashMap。
- LinkedHashSet:内部是LinkedHashMap。
- TreeSet:内部是TreeMap的SortedSet。
- ConcurrentSkipListSet:内部是ConcurrentSkipListMap的并发优化的SortedSet。
- CopyOnWriteArraySet:内部是CopyOnWriteArrayList的并发优化的Set,利用其addIfAbsent()方法实现元素去重,如前所述该方法的性能很一般。
补充:好像少了个ConcurrentHashSet,本来也该有一个内部用ConcurrentHashMap的简单实现,但JDK偏偏没提供。Jetty就自己封了一个,Guava则直接用java.util.Collections.newSetFromMap(new ConcurrentHashMap()) 实现。
Queue
Queue是在两端出入的List,所以也可以用数组或链表来实现。
–普通队列–
LinkedList
是的,以双向链表实现的LinkedList既是List,也是Queue。它是唯一一个允许放入null的Queue。
ArrayDeque
以循环数组实现的双向Queue。大小是2的倍数,默认是16。
普通数组只能快速在末尾添加元素,为了支持FIFO,从数组头快速取出元素,就需要使用循环数组:有队头队尾两个下标:弹出元素时,队头下标递增;加入元素时,如果已到数组空间的末尾,则将元素循环赋值到数组[0](如果此时队头下标大于0,说明队头弹出过元素,有空位),同时队尾下标指向0,再插入下一个元素则赋值到数组[1],队尾下标指向1。如果队尾的下标追上队头,说明数组所有空间已用完,进行双倍的数组扩容。
PriorityQueue
用二叉堆实现的优先级队列,详见入门教程,不再是FIFO而是按元素实现的Comparable接口或传入Comparator的比较结果来出队,数值越小,优先级越高,越先出队。但是注意其iterator()的返回不会排序。
–线程安全的队列–
ConcurrentLinkedQueue/ConcurrentLinkedDeque
无界的并发优化的Queue,基于链表,实现了依赖于CAS的无锁算法。
ConcurrentLinkedQueue的结构是单向链表和head/tail两个指针,因为入队时需要修改队尾元素的next指针,以及修改tail指向新入队的元素两个CAS动作无法原子,所以需要的特殊的算法,篇幅所限见入门教程。
PriorityBlockingQueue
无界的并发优化的PriorityQueue,也是基于二叉堆。使用一把公共的读写锁。虽然实现了BlockingQueue接口,其实没有任何阻塞队列的特征,空间不够时会自动扩容。
DelayQueue
内部包含一个PriorityQueue,同样是无界的。元素需实现Delayed接口,每次调用时需返回当前离触发时间还有多久,小于0表示该触发了。
pull()时会用peek()查看队头的元素,检查是否到达触发时间。ScheduledThreadPoolExecutor用了类似的结构。
–线程安全的阻塞队列–
BlockingQueue的队列长度受限,用以保证生产者与消费者的速度不会相差太远,避免内存耗尽。队列长度设定后不可改变。当入队时队列已满,或出队时队列已空,不同函数的效果见下表: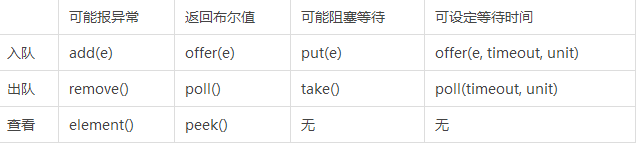
ArrayBlockingQueue
定长的并发优化的BlockingQueue,基于循环数组实现。有一把公共的读写锁与notFull、notEmpty两个Condition管理队列满或空时的阻塞状态。
LinkedBlockingQueue/LinkedBlockingDeque
可选定长的并发优化的BlockingQueue,基于链表实现,所以可以把长度设为Integer.MAX_VALUE。利用链表的特征,分离了takeLock与putLock两把锁,继续用notEmpty、notFull管理队列满或空时的阻塞状态。
补充
JDK7有个LinkedTransferQueue,transfer(e)方法保证Producer放入的元素,被Consumer取走了再返回,比SynchronousQueue更好,有空要学习下。
来源:http://www.topthink.com/topic/11679.html
